
iterable和iterator很容易弄混的吧!
定义
Iterator
An object representing a stream of data.
我们可以从Python官方的文档中了解到,Iterator - 迭代器 这个术语在python中的意义。
Iterator - 可以表示数据流的对象。
数据流 - 一组有顺序的(线性的)、有起点和终点的数据集合。
就像在管道中流淌的水流,数据流通常都是单向的。Python允许我们通过调用一个iterator对象上的__next__()方法,来访问数据流(iterator)中的下一个元素。另一种方法是使用内置函数next(),使用next(iterator_object)来获取iterator中的下一个元素。我们可以在同一个iterator上重复进行这样的操作,最终会按顺序获取数据流中的所有对象。
当iterator中的最后一个元素已经被访问之后,我们再使用next()方法,或者调用__next__(),解释器会抛出一个StopIteration异常,告诉我们此迭代器之前就已经迭代结束了,其中已经没有“下一个”元素了。
由此,我们可以简单地认为:如果一个对象拥有__next__()方法,我们就可以视它为iterator。
Iterable
An object capable of returning its members one at a time.
Iterable - 有能力一次性返回它的成员的对象。
这里需要解释这个“成员”是个带s的复数。
这个对象有一个方法来返回它容纳的一些元素,甚至全部元素。我们就可以称它为可迭代对象iterable。
怎么做到一次返回全部元素?这里不要产生理解偏差,不是指返回一个数组,其实是特指返回一个iterator。
我们学习过的所有线性数据类型,包括list, str, tuple,一些非线性数据类型,包括dict和open()函数返回的文件对象,都是可迭代对象。它们都有一个叫做__iter__()的方法,可以返回它们各自的迭代器。我们也可以使用内置函数iter(),传入一个可迭代对象,就可以返回一个它的迭代器对象。
另外,文档中明确说明了,任何定义了__iter__()或__getitem__()的对象,都是iterable。但是要求__getitem__()方法实现的是一个线性的语义。这样是为了让其在for语法下与可迭代对象表现出同样的行为,为了让其生成的迭代器与其他迭代器同样是一个数据流。(如果__getitem__()实现的并不是线性的语义,解释器并不会报错,同样可以被for语法使用。但是语义错误同样是编程错误。)
可迭代对象一定是一个线性的数据类型。大部分线性的数据类型都是一个iterable。
我们可以简单地认为,只要实现了__iter__()或__getitem__()方法的类,其对象都是iterable。
for…in
1 | L = ['python', 'java', 'rust', 'c'] |
所以我们可以明白for...in的语法到底为我们做了啥。
首先for item in L,会在L这个iterable上调用__iter__(),创建一个iterator对象,然后每轮循环都在在iterator上调用__next__()并把返回值赋给item,直到出现StopIteration异常,帮我们捕获后就会结束循环。
自己动手
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
Python推崇鸭子类型,你如果实现了__iter__()或__getitem__()方法,(即把对象传入iter()可以得到一个Iterator)那你就是一个Iterable。同理,你如果实现了__next__()和__iter__()就是一个Iterator。有时候,鸭子类型可以让我们很方便地免去继承来实现一些interface或者说是protocol。
自己的Iterator
由文档中对于迭代器的类型的描述,我们得知,迭代器类必须实现一个__next__()方法用于返回下一个迭代元素,还有一个__iter__()方法返回自身。
1 | class MyRange: |
上面的代码实现了我们自己的range(),MyRange类实例化后产生的对象就是一个iterator。我们可以使用for循环对这个iterator进行迭代,等等!for…in的迭代对象不是iterable吗?为什么我们写的iterator也可以被for语法遍历呢?
写代码让我们发现了python规定迭代器类必须实现__iter__()的理由,很多时候我只是需要一个迭代器,但事实上很多地方使用的是可迭代对象协议。可迭代对象需要实现的是可以把迭代器返回出来,那么我们的迭代器自己实现__iter__()并且把自己返回出来,其实逻辑上是可以接受的。
对iterator进行迭代,是符合直觉的,因为迭代器本来就是可以迭代的。
对iterable进行迭代,也是符合直觉的,“可迭代的对象”本来也是可迭代的,每次迭代的时候在内部初始化一个iterator进行迭代。
iterator一定是一个iterable。
自己的Iterable
所以其实iterable就没有必要实现了,上面的MyRange本身就是一个iterable。
但你还记得上面定义吗,一个实现了线性语义的__getitem__()方法的对象也是一个iterable。另外还要求了__getitem__()方法的接收的参数是从0开始的整数。
object must be a collection object which supports the iteration protocol (the
__iter__()method), or it must support the sequence protocol (the__getitem__()method with integer arguments starting at 0).
1 | class MyRange: |
这样实现的MyRange,是一个单纯的iterable。内置函数iter(),可以神奇地把它的对象转变成一个iterator。因为可以线性遍历元素的容器,在逻辑结构上是满足迭代器的结构的。
判断可迭代对象
for语法能不能作用在一个对象上?(这个对象是不是一个iterable或者iterator)
一个对象能不能作为next()函数的第一个参数?(这个对象是不是一个iterator)
在动态类型的python中,有时必要的类型判断可以避免很多问题。
在网上搜索,很多文章给出的判断方法是:
1 | >> from collections import Iterable |
然后我得到的结果是:
1 | >> from collections import Iterable |
我目前使用的是Python 3.7.4,Warning中也明确说了,3.8以后我们就不能再从collections中import或者使用ABCs(Abstract Base Classes)。所以我们得改成:
1 | >> from collections.abc import Iterable, Iterator |
Generator
生成器本身一定是Iterator,并且它也可以用于实现iterable的__iter__()方法。有两种方法可以方便地创建生成器,其中第二种方法涉及到yield语句,我不想再展开说,以后如果有时间再另写一篇关于yield语句以及和它有关的协程。
生成器表达式
1 | >> g = (num for num in range(4,9)) |
生成器函数
1 | def my_range(low, high): |
尾巴
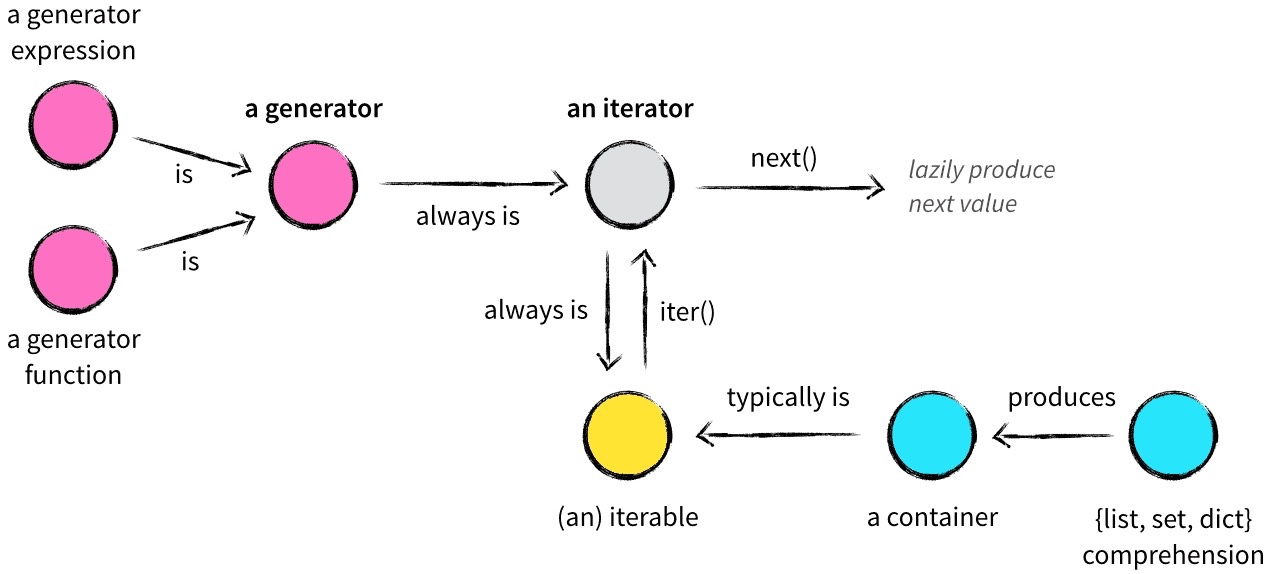
最后用一张来自Vincent Driessen的一篇博文Iterables vs. Iterators vs. Generators的图片来总结下:
很长时间没用就是会让记忆变得模糊哈,多查文档多用搜索引擎,python的文档真的很棒,希望你们都学得开心。